
RStudio snippets are very handy when it comes to dealing with repetitive tasks. Here is how to modify RStudio snippets or create a new one.
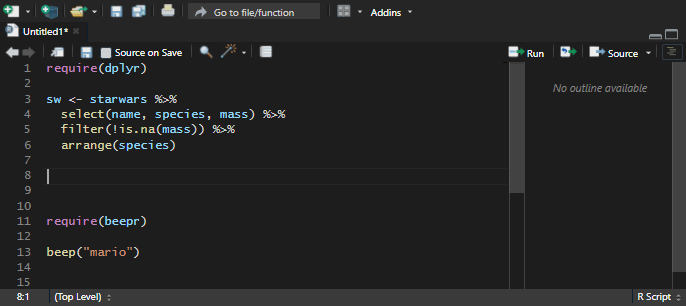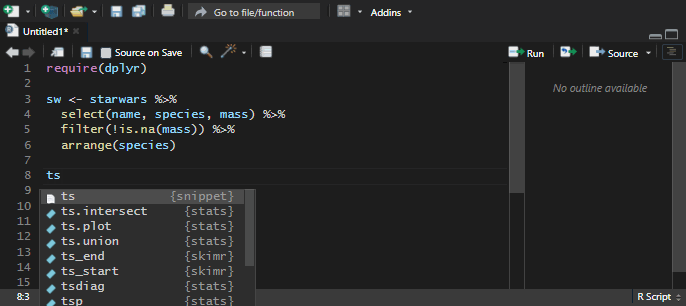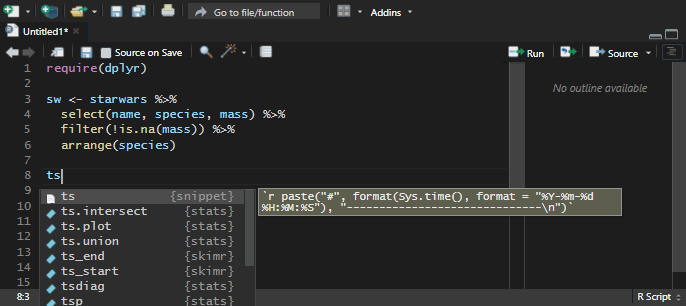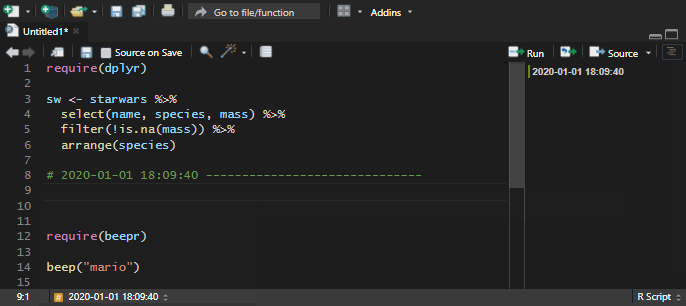
In my case, there was a problem with the format that I get by using the ts snippet.

Modify RStudio snippets
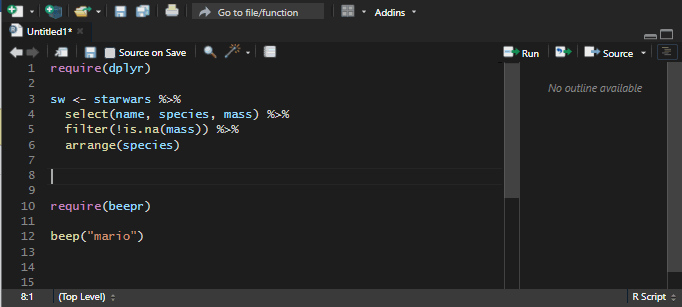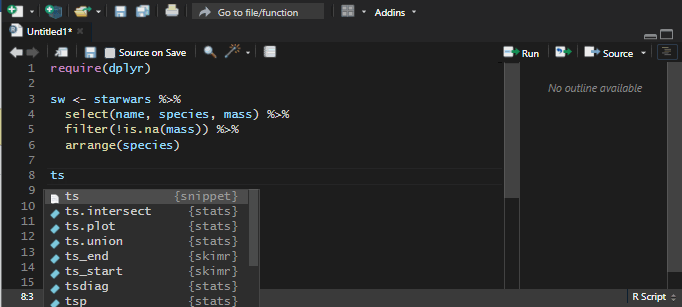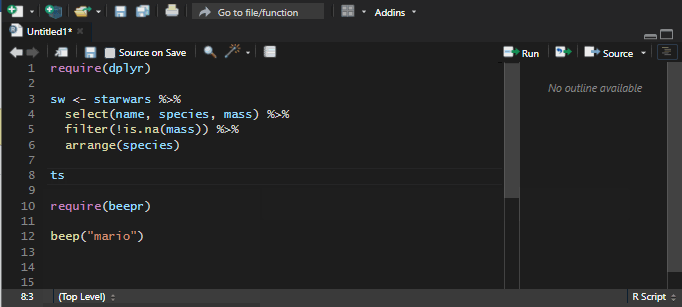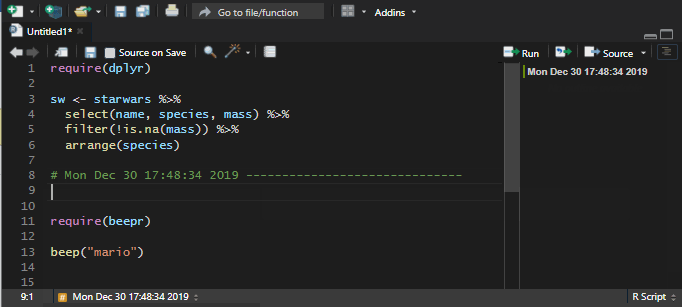
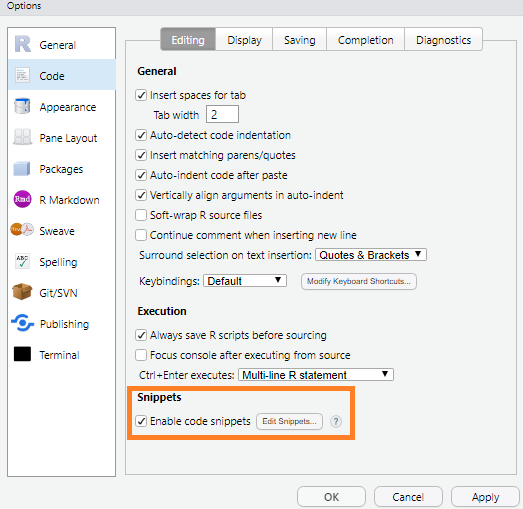
To change or create new snippet go to Tools -> Global Options -> Code -> Edit Snippets.

After that, I located the ts snippet.


To get my desired date-time format, I replaced the date function with this and saved snippets.
format(Sys.time(), format = "%Y-%m-%d %H:%M:%S")



You can enhance productivity in RStudio by making RProfile modifications. Take a look at this post on how to do that and why.
I love the post. most of my snippets are working fine, however, I cannot get a certain nippet to populate when I type the name.
Do you know if Rstudio snippets have size limitations?
Is my snippet formatted incorrectly?
Here is the code. (sorry it’s kind of big.)
snippet supersense
sentiment_analysis %
select(${2:columns}, text)
sentiment_analysis %
unnest_tokens(word, text)
custom_stop <- c("get", "can")
sentiment_analysis %
anti_join(get_stopwords()) %>%
filter(!word %in% custom_stop)
sentiment_analysis %
full_join(get_sentiments(“nrc”)) %>%
group_by(${2:columns}, sentiment) %>%
summarize(count = n()) %>%
na.omit() %>%
pivot_wider(names_from = sentiment, values_from = count) %>%
mutate(across(everything(), ~ replace_na(.x, 0))) %>%
ungroup() %>%
full_join(sentiment_analysis)
sentiment_analysis %
full_join(get_sentiments(“afinn”)) %>%
group_by(${2:columns}) %>%
summarize(positivity_weights = mean(value, na.rm = TRUE)) %>%
ungroup() %>%
full_join(sentiment_analysis)
sentiment_analysis %
full_join(get_sentiments(“bing”)) %>%
group_by(${2:columns}, sentiment) %>%
summarize(count = n()) %>%
na.omit() %>%
pivot_wider(names_from = sentiment, values_from = count) %>%
mutate(
across(c(positive, negative), ~ replace_na(.x, 0)),
positivity_binary = (positive – negative) / sum(positive, negative, na.rm = TRUE)
) %>%
ungroup() %>%
select(-positive,-negative) %>%
full_join(sentiment_analysis)${1:dataset} % select(-word) %>%
distinct() %>%
full_join(${1:dataset}, by = c(” ${3:samecolumns} “))