If you want to count values excluding NA in R, here is a simple way to do that. You can detect non-NA values and get results as TRUE or FALSE that can be used by the sum function to get the result.
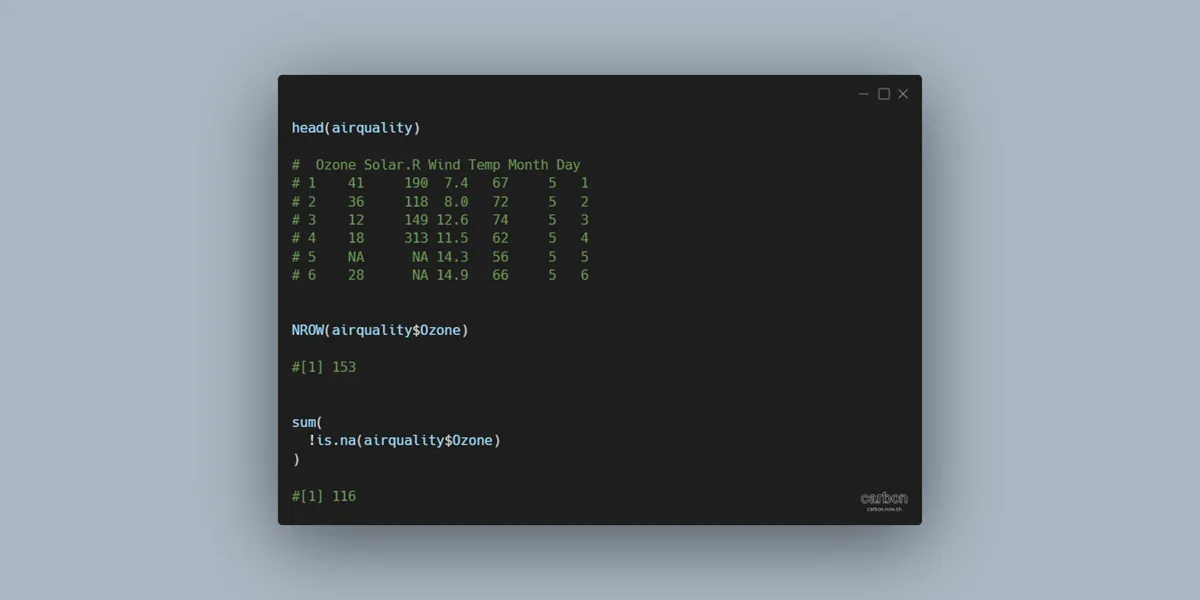
Here is the airquality data set from R. First column contains NA values, but I would like to count all values in that column, excluding NA.
head(airquality) # Ozone Solar.R Wind Temp Month Day # 1 41 190 7.4 67 5 1 # 2 36 118 8.0 72 5 2 # 3 12 149 12.6 74 5 3 # 4 18 313 11.5 62 5 4 # 5 NA NA 14.3 56 5 5 # 6 28 NA 14.9 66 5 6
Here is the number of total rows.
NROW(airquality$Ozone) #[1] 153
If you have to do calculations with the sum function, it contains an argument to remove NA values, but there is not that kind of option for counting. Luckily you can sum all the indicators that show where the values are not missing.
Count excluding NA in R
Here is how to get non-missing value indicators.
head( !is.na(airquality$Ozone) ) #[1] TRUE TRUE TRUE TRUE FALSE TRUE
That leads to the count excluding NA values.
sum( !is.na(airquality$Ozone) ) #[1] 116
You can convert TRUE and FALSE to 1 and 0 in R, but that makes no difference in the previous calculation.
head( as.integer(!is.na(airquality$Ozone)) ) #[1] 1 1 1 1 0 1
Count non-NA values in a row or column
You can easily count excluding NA values in all rows or columns with the functions rowSums and colSums. Here is how to do that.
head( rowSums(!is.na(airquality)) ) #[1] 6 6 6 6 4 5 colSums(!is.na(airquality)) # Ozone Solar.R Wind Temp Month Day # 116 146 153 153 153 153
Here is how to do the opposite and get a summary of NA values in the R data frame.
Count non-missing values by the group in R
If you want to count by the group in R and, in this case, count non-missing values, try this approach using the package dplyr. Here is how to count non-NA values by filtering out the component that you don’t want to use.
require(dplyr) airquality %>% filter(!is.na(Ozone)) %>% group_by(Month) %>% count(name = "non-NA values in column Ozone by Month") # Month non-NA values in column Ozone by Month # 1 5 26 # 2 6 9 # 3 7 26 # 4 8 26 # 5 9 29
It is possible to summarise and calculate the difference with the total rows in the group.
airquality %>%
group_by(Month) %>%
summarise("non-NA values in column Ozone by Month" = sum(!is.na(Ozone)),
"all rows by Month" = n(),
"difference" = `all rows by Month` - `non-NA values in column Ozone by Month`)
# Month non-NA values in column Ozone by Month all rows by Month difference
# 1 5 26 31 5
# 2 6 9 30 21
# 3 7 26 31 5
# 4 8 26 31 5
# 5 9 29 30 1
Here is how to do that and other useful tips and tricks for counting in R.
If you love to work with other tasks using the dplyr, here are my top 10 favorite tips and tricks that can help to increase productivity.
Leave a Reply