Here is how to pivot data in R from long to wide format and increase the number of columns. This transformation might be familiar to Microsoft Excel users because of the PivoTable tool. It might not be the most commonly used data transformation, but sometimes necessary to show data in a small table or transform for the input in other visualization.
To pivot the data frame in R from long to wide format, I will apply the function pivot_wider from the tidyr. This function is relatively easy to use. I think it is one of to most popular choices to do this task.
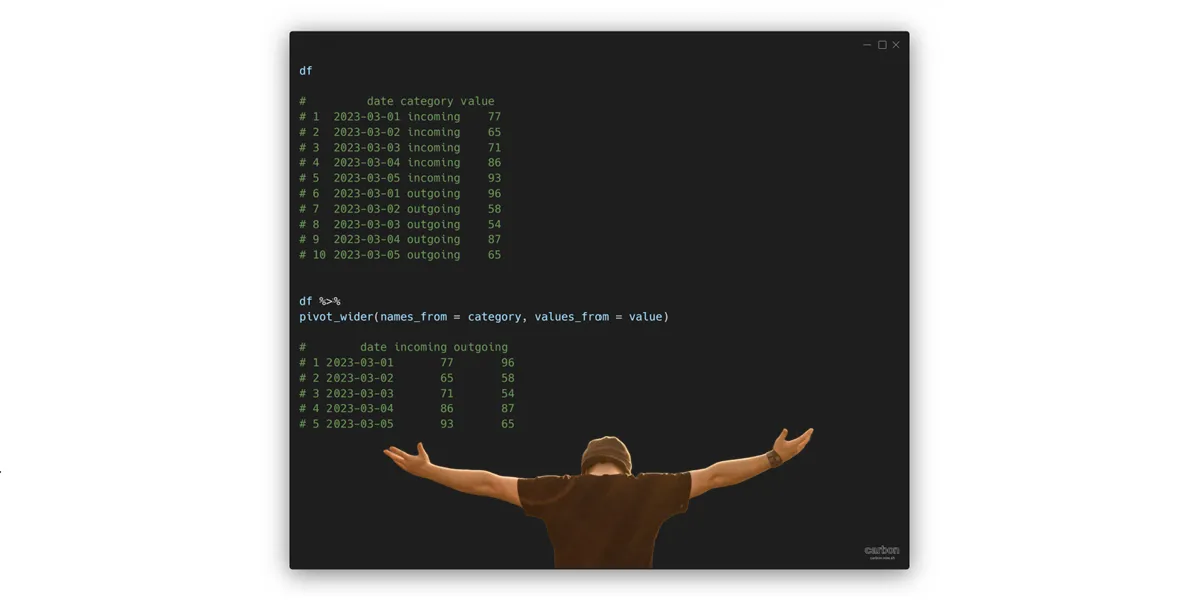
Here is my data frame that contains randomly generated values. Here is more about that.
mydates <- seq(as.Date("2023-03-01"), as.Date("2023-03-05"), by = "day")
set.seed(1234)
df <-
rbind(
data.frame(
"date" = mydates,
"category" = "incoming",
"value" = sample(50:100, 5, replace = TRUE)
),
data.frame(
"date" = mydates,
"category" = "outgoing",
"value" = sample(50:100, 5, replace = TRUE)
)
)
df
# date category value
# 1 2023-03-01 incoming 77
# 2 2023-03-02 incoming 65
# 3 2023-03-03 incoming 71
# 4 2023-03-04 incoming 86
# 5 2023-03-05 incoming 93
# 6 2023-03-01 outgoing 96
# 7 2023-03-02 outgoing 58
# 8 2023-03-03 outgoing 54
# 9 2023-03-04 outgoing 87
# 10 2023-03-05 outgoing 65
Pivot data frame in R
Here is how you can pivot a simple data frame in R and specify which column will separate values in multiple columns.
require(dplyr) require(tidyr) df %>% pivot_wider(names_from = category, values_from = value) # date incoming outgoing # 1 2023-03-01 77 96 # 2 2023-03-02 65 58 # 3 2023-03-03 71 54 # 4 2023-03-04 86 87 # 5 2023-03-05 93 65
Pivot wider in R using multiple columns
In the pivot_wider function, you can use values from multiple columns like this. Here is the additional calculation for another value column and the result of the pivot.
df$calc <- df$value / 10 df %>% pivot_wider(names_from = category, values_from = c(value, calc)) # date value_incoming value_outgoing calc_incoming calc_outgoing # 1 2023-03-01 77 96 7.7 9.6 # 2 2023-03-02 65 58 6.5 5.8 # 3 2023-03-03 71 54 7.1 5.4 # 4 2023-03-04 86 87 8.6 8.7 # 5 2023-03-05 93 65 9.3 6.5
If you pivot data like in the first example with only one value column, the other column creates unwanted effects on the result.
df %>% pivot_wider(names_from = category, values_from = value) # date calc incoming outgoing # 1 2023-03-01 7.7 77 NA # 2 2023-03-02 6.5 65 NA # 3 2023-03-03 7.1 71 NA # 4 2023-03-04 8.6 86 NA # 5 2023-03-05 9.3 93 NA # 6 2023-03-01 9.6 NA 96 # 7 2023-03-02 5.8 NA 58 # 8 2023-03-03 5.4 NA 54 # 9 2023-03-04 8.7 NA 87 # 10 2023-03-05 6.5 NA 65
It is possible to ignore some of the columns in the pivot_wider by specifying the id column or multiple id columns.
df %>%
pivot_wider(id_cols = date,
names_from = category,
values_from = value)
# date incoming outgoing
# 1 2023-03-01 77 96
# 2 2023-03-02 65 58
# 3 2023-03-03 71 54
# 4 2023-03-04 86 87
# 5 2023-03-05 93 65
tidyr pivot_wider with function like ifelse
If you are using dplyr, it is easy to integrate functions like mutate into the data transformation process. For example, here is how to transform one of the columns with the function ifelse and use the result in the pivot_wider.
df %>%
mutate("value" = ifelse(category == "outgoing", value * -1, value)) %>%
pivot_wider(id_cols = date,
names_from = category,
values_from = value)
# date incoming outgoing
# 1 2023-03-01 77 -96
# 2 2023-03-02 65 -58
# 3 2023-03-03 71 -54
# 4 2023-03-04 86 -87
# 5 2023-03-05 93 -65
tidyr pivot_wider with additional calculation
Here is a data frame with random dates in a certain date interval and random numbers.
set.seed(1234)
d1 <- sample(seq(as.Date("2023-03-01"), as.Date("2023-03-15"), by = "day"), 10, replace = TRUE)
x <- runif(10, min = 1, max=10)
d2 <- sample(seq(as.Date("2023-03-01"), as.Date("2023-03-15"), by = "day"), 10, replace = TRUE)
y <- runif(10, min = 1, max=10)
df <- rbind(data.frame("date" = d1, "category" = "incoming", "value" = x),
data.frame("date" = d2, "category" = "outgoing", "value" = y))
ds <-
data.frame("date" = seq.Date(
from = as.Date("2023-03-01"),
to = as.Date("2023-03-15"),
by = 'days'
))
df <- left_join(ds, df, multiple = "all") %>%
arrange(date)
As you can see, the data contains multiple records for some of the dates and categories.
head(df) # date category value # 1 2023-03-01 NA NA # 2 2023-03-02 NA NA # 3 2023-03-03 outgoing 5.980002 # 4 2023-03-04 incoming 3.724240 # 5 2023-03-04 outgoing 2.629866 # 6 2023-03-04 outgoing 7.837036
It is necessary to pivot summarized data. One of the ways is to sum by the group before using the pivot_wider, but you can do simple calculations together with pivoting.
df %>%
pivot_wider(names_from = category,
values_from = value,
values_fn = sum) %>%
select(-"NA")
# date outgoing incoming
# 1 2023-03-01 NA NA
# 2 2023-03-02 NA NA
# 3 2023-03-03 5.980002 NA
# 4 2023-03-04 27.213910 3.724240
# 5 2023-03-05 2.811232 11.625694
# 6 2023-03-06 NA 7.480355
# 7 2023-03-07 NA NA
# 8 2023-03-08 15.337509 NA
# 9 2023-03-09 NA 2.680505
# 10 2023-03-10 NA 9.310901
# 11 2023-03-11 NA NA
# 12 2023-03-12 NA 7.120612
# 13 2023-03-13 NA NA
# 14 2023-03-14 5.565762 NA
# 15 2023-03-15 NA 3.401387
The category column contains NA values, and I used the function select to exclude that from the results.
Here is how you can execute more complex calculations in the pivot_wider, like summarizing and rounding the result.
df %>%
pivot_wider(
names_from = category,
values_from = value,
values_fn = function(x)
round(sum(x, na.rm = TRUE), digits = 1)) %>%
select(-"NA")
# date outgoing incoming
# 1 2023-03-01 NA NA
# 2 2023-03-02 NA NA
# 3 2023-03-03 6.0 NA
# 4 2023-03-04 27.2 3.7
# 5 2023-03-05 2.8 11.6
# 6 2023-03-06 NA 7.5
# 7 2023-03-07 NA NA
# 8 2023-03-08 15.3 NA
# 9 2023-03-09 NA 2.7
# 10 2023-03-10 NA 9.3
# 11 2023-03-11 NA NA
# 12 2023-03-12 NA 7.1
# 13 2023-03-13 NA NA
# 14 2023-03-14 5.6 NA
# 15 2023-03-15 NA 3.4
Pivot wider in R and replace missing values
If the context allows you to replace missing values, you can do that with an additional argument in the pivot_wider.
df %>%
pivot_wider(
names_from = category,
values_from = value,
values_fn = function(x)
round(sum(x, na.rm = TRUE), digits = 1),
values_fill = 0) %>%
select(-"NA")
# date outgoing incoming
# 1 2023-03-01 0.0 0.0
# 2 2023-03-02 0.0 0.0
# 3 2023-03-03 6.0 0.0
# 4 2023-03-04 27.2 3.7
# 5 2023-03-05 2.8 11.6
# 6 2023-03-06 0.0 7.5
# 7 2023-03-07 0.0 0.0
# 8 2023-03-08 15.3 0.0
# 9 2023-03-09 0.0 2.7
# 10 2023-03-10 0.0 9.3
# 11 2023-03-11 0.0 0.0
# 12 2023-03-12 0.0 7.1
# 13 2023-03-13 0.0 0.0
# 14 2023-03-14 5.6 0.0
# 15 2023-03-15 0.0 3.4
Look at this post, if you want to use trailing zeros.
Leave a Reply