Here are multiple examples of how to count by group in R using base, dplyr, and data table capabilities. Dplyr might be the first choice to count by the group because it is relatively easy to adjust to specific needs.
Meanwhile data.table is good for speed, and base R sometimes is good enough.
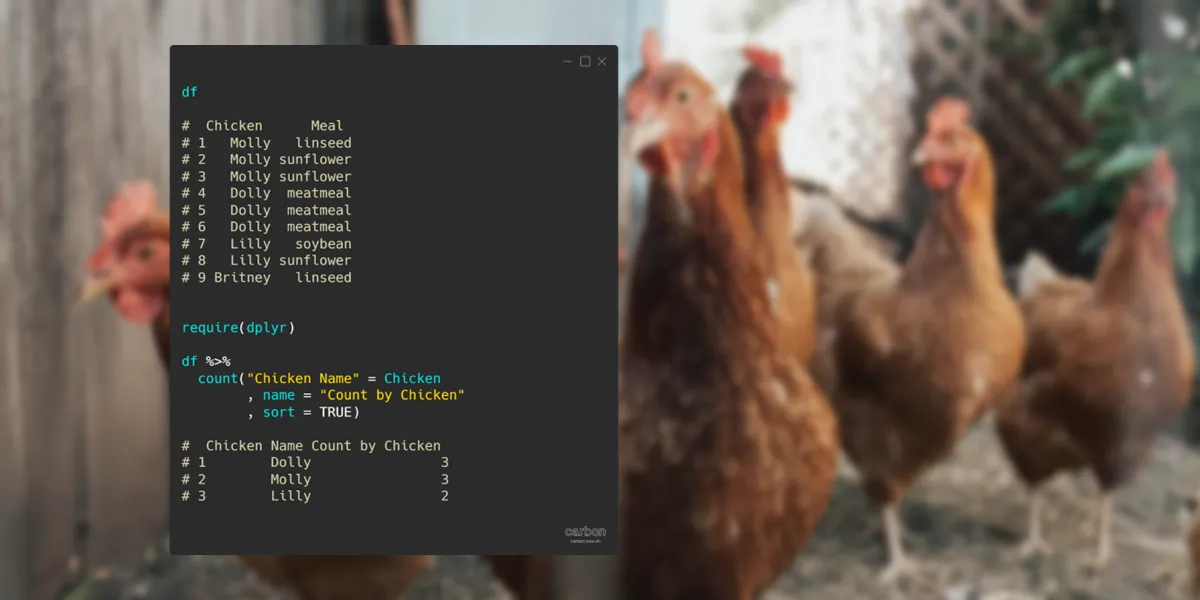
Here is my data set.
df <- structure(list(Chicken = c("Molly", "Molly", "Molly",
"Dolly", "Dolly", "Dolly",
"Lilly", "Lilly", "Britney"),
Meal = c("linseed", "sunflower", "sunflower",
"meatmeal", "meatmeal", "meatmeal",
"soybean", "sunflower", "linseed")),
class = "data.frame", row.names = c(NA, -9L))
df
# Chicken Meal
# 1 Molly linseed
# 2 Molly sunflower
# 3 Molly sunflower
# 4 Dolly meatmeal
# 5 Dolly meatmeal
# 6 Dolly meatmeal
# 7 Lilly soybean
# 8 Lilly sunflower
# 9 Britney linseed
dplyr count by group
If you are looking for a count function in R, then in the base R is none with that name. Meanwhile, there is a count function in dplyr, and here are tips and tricks mainly on how to use that.
require(dplyr)
df %>%
count("Chicken Name" = Chicken
, name = "Count by Chicken"
, sort = TRUE)
# Chicken Name Count by Chicken
# 1 Dolly 3
# 2 Molly 3
# 3 Lilly 2
# 4 Britney 1Here is how to count by multiple groups.
df %>%
count(Chicken, Meal
, name = "Count by Chicken and Meal"
, sort = TRUE)
# Chicken Meal Count by Chicken and Meal
# 1 Dolly meatmeal 3
# 2 Molly sunflower 2
# 3 Britney linseed 1
# 4 Lilly soybean 1
# 5 Lilly sunflower 1
# 6 Molly linseed 1If there is a missing value and you don’t want to count them, use the dplyr filter function before counting.
Add count by group but don’t summarise in dplyr
By using the function add_count, you can quickly get a column with a count by the group and keep records ungrouped. It is a simpler solution to get the same result as with the function group_by and mutate.
df %>% add_count(Chicken, name = "Count by Chicken") # Chicken Meal Count by Chicken # 1 Molly linseed 3 # 2 Molly sunflower 3 # 3 Molly sunflower 3 # 4 Dolly meatmeal 3 # 5 Dolly meatmeal 3 # 6 Dolly meatmeal 3 # 7 Lilly soybean 2 # 8 Lilly sunflower 2 # 9 Britney linseed 1
dplyr count distinct values by group
Here is how to count only distinct values by the group in R using dplyr.
df %>%
distinct(Meal, .keep_all = TRUE) %>%
count("Chicken Name" = Chicken
, name = "Distinct Meal Types by Chicken"
, sort = TRUE)
# Chicken Name Distinct Meal Types by Chicken
# 1 Molly 2
# 2 Dolly 1
# 3 Lilly 1There is a way to get distinct values and keep the last one. In this situation, it makes no difference, but sometimes it is good to know.
dplyr count unique values by group
In this scenario, I am considering unique values only those who are only once in the group. By using the previous technique, let’s look at how the count by chicken and meal looks in an ungrouped data frame.
df %>% add_count(Chicken, Meal, name = "Count by Chicken and Meal") # Chicken Meal Count by Chicken # 1 Molly linseed 1 # 2 Molly sunflower 2 # 3 Molly sunflower 2 # 4 Dolly meatmeal 3 # 5 Dolly meatmeal 3 # 6 Dolly meatmeal 3 # 7 Lilly soybean 1 # 8 Lilly sunflower 1 # 9 Britney linseed 1
One way is to filter those meals that appear only once for each chicken. I want to show the whole picture. By using mutate, I can modify results and replace the count for meals that are not unique with zero and summarize by each chicken.
df %>%
add_count(Chicken, Meal, name = "Count by Chicken and Meal") %>%
mutate(`Unique by Chicken and Meal` =
if_else(`Count by Chicken and Meal` == 1, 1, 0)) %>%
group_by("Chicken Name" = Chicken) %>%
summarise("Unique Meal Types by Chicken" = sum(`Unique by Chicken and Meal`)) %>%
arrange(desc(`Unique Meal Types by Chicken`)) %>%
print.data.frame()
# Chicken Name Unique Meal Types by Chicken
# 1 Lilly 2
# 2 Britney 1
# 3 Molly 1
# 4 Dolly 0Here you can learn more about how to sum by a group in R.
Count by group in data.table
Here is how to count by group using data.table.
require(data.table)
df <- as.data.table(df)
df[, list("Count by Chicken" = .N), by = list("Chicken Name" = Chicken)]
# Chicken Name Count by Chicken
# 1: Molly 3
# 2: Dolly 3
# 3: Lilly 2
# 4: Britney 1Here is how to count by multiple groups using data.table in order by the result.
df[, list("Count by Chicken and Meal" = .N)
, by = list("Chicken Name" = Chicken, Meal)][
order(`Count by Chicken and Meal`, decreasing = TRUE)]
# Chicken Name Meal Count by Chicken and Meal
# 1: Dolly meatmeal 3
# 2: Molly sunflower 2
# 3: Molly linseed 1
# 4: Lilly soybean 1
# 5: Lilly sunflower 1
# 6: Britney linseed 1
Count by group in base R
aggregate(cbind("Count by Chicken" = Meal) ~ Chicken,
data = df,
FUN = NROW)
# Chicken Count by Chicken
# 1 Britney 1
# 2 Dolly 3
# 3 Lilly 2
# 4 Molly 3Count by group using multiple columns in base R.
aggregate(cbind("Count by Chicken and Meal" = Meal) ~ Chicken + Meal,
data = df,
FUN = NROW)
# Chicken Meal Count by Chicken and Meal
# 1 Britney linseed 1
# 2 Molly linseed 1
# 3 Dolly meatmeal 3
# 4 Lilly soybean 1
# 5 Lilly sunflower 1
# 6 Molly sunflower 2If you need to sort the results of the function aggregate, try base R function order. It is worth mentioning that the function NROW will count missing values. Here is how to count by excluding NA.
Here are additional resources that might help in other situations. Here is how to count by excluding NA in R or helpful tips and tricks for using counting.
If you are using dplyr, here are helpful tips and tricks for that.
One of the most popular functions in dplyr is the mutate, and you can use that to get addition columns with count or result of other operations.
Leave a Reply