Here are two methods how to get the previous or next record in the R data frame. One of them is better in large data frames, but the other is more compact.
Here is the data frame that I created as a reproducible R data frame.
df <- structure(list(year = c(2015L, 2016L, 2017L, 2018L, 2019L, 2020L, 2015L, 2016L, 2017L, 2018L, 2019L, 2020L), category = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L), .Label = c("A", "B"), class = "factor"), value = c(28L, 41L, 71L, 92L, 39L, 64L, 25L, 21L, 17L, 59L, 38L, 97L)), class = "data.frame", row.names = c(NA, -12L))
df %>% knitr::kable()
#| year|category | value|
#|----:|:--------|-----:|
#| 2015|A | 28|
#| 2016|A | 41|
#| 2017|A | 71|
#| 2018|A | 92|
#| 2019|A | 39|
#| 2020|A | 64|
#| 2015|B | 25|
#| 2016|B | 21|
#| 2017|B | 17|
#| 2018|B | 59|
#| 2019|B | 38|
#| 2020|B | 97|Dealing with subgroups in R data frame
If you have subgroups in your data frame, then you have to consider that. Previous or the next value might appear from the different groups of data.
A simple method to get previous or next record with R
Order the data in the right way.
The next record in R
For the next record, you have to return the same column, but remove the first record and add NA at the end or other appropriate values.
df <- transform(df, nxt_value = c(value[-1], NA)) df %>% knitr::kable() #| year|category | value| nxt_value| #|----:|:--------|-----:|---------:| #| 2015|A | 28| 41| #| 2016|A | 41| 71| #| 2017|A | 71| 92| #| 2018|A | 92| 39| #| 2019|A | 39| 64| #| 2020|A | 64| 25| #| 2015|B | 25| 21| #| 2016|B | 21| 17| #| 2017|B | 17| 59| #| 2018|B | 59| 38| #| 2019|B | 38| 97| #| 2020|B | 97| NA|
If you are dealing with subgroups in data like I do, then check if the next row contains the same category.
df <- transform(df, nxt_cat = c(as.character(category[-1]), NA)) df$nxt_value <- ifelse(df$nxt_cat == df$category, df$nxt_value, NA) df %>% knitr::kable() #| year|category | value| nxt_value|nxt_cat | #|----:|:--------|-----:|---------:|:-------| #| 2015|A | 28| 41|A | #| 2016|A | 41| 71|A | #| 2017|A | 71| 92|A | #| 2018|A | 92| 39|A | #| 2019|A | 39| 64|A | #| 2020|A | 64| NA|B | #| 2015|B | 25| 21|B | #| 2016|B | 21| 17|B | #| 2017|B | 17| 59|B | #| 2018|B | 59| 38|B | #| 2019|B | 38| 97|B | #| 2020|B | 97| NA|NA |
The previous record in R
For the previous record, you have to remove the last entry of the column and add NA at the start of the column or other appropriate value.
If you are dealing with subgroups in data like I do, check if the previous row contains the same category.
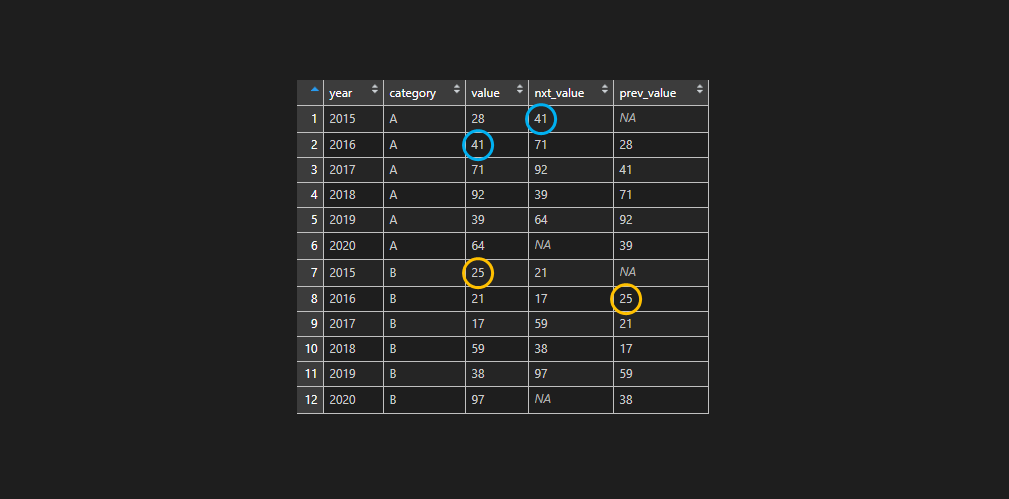
df <- transform(df, prev_value = c(NA, value[-length(value)])) df <- transform(df, prev_cat = c(NA, as.character(category[-length(category)]))) df$prev_value <- ifelse(df$prev_cat == df$category, df$prev_value, NA) df %>% knitr::kable() #| year|category | value| nxt_value|nxt_cat | prev_value|prev_cat | #|----:|:--------|-----:|---------:|:-------|----------:|:--------| #| 2015|A | 28| 41|A | NA|NA | #| 2016|A | 41| 71|A | 28|A | #| 2017|A | 71| 92|A | 41|A | #| 2018|A | 92| 39|A | 71|A | #| 2019|A | 39| 64|A | 92|A | #| 2020|A | 64| NA|B | 39|A | #| 2015|B | 25| 21|B | NA|A | #| 2016|B | 21| 17|B | 25|B | #| 2017|B | 17| 59|B | 21|B | #| 2018|B | 59| 38|B | 17|B | #| 2019|B | 38| 97|B | 59|B | #| 2020|B | 97| NA|NA | 38|B |
Previous or next record with dplyr
Order the data in the right way.
There are functions lag and lead that are great and easy to use but might be slow for bigger datasets.
In this example, I’m dealing with multiple categories, and it is necessary to ensure that the work takes place within the category.
The next record with dplyr
require(dplyr)
df <- df %>% group_by(category) %>% mutate("nxt_value" = lead(value))
df %>% knitr::kable()
#| year|category | value|
#|----:|:--------|-----:|
#| 2015|A | 28|
#| 2016|A | 41|
#| 2017|A | 71|
#| 2018|A | 92|
#| 2019|A | 39|
#| 2020|A | 64|
#| 2015|B | 25|
#| 2016|B | 21|
#| 2017|B | 17|
#| 2018|B | 59|
#| 2019|B | 38|
#| 2020|B | 97|The previous record with dplyr
require(dplyr)
df <- df %>% group_by(category) %>% mutate("prev_value" = lag(value))
df %>% knitr::kable()
#| year|category | value| prev_value|
#|----:|:--------|-----:|----------:|
#| 2015|A | 28| NA|
#| 2016|A | 41| 28|
#| 2017|A | 71| 41|
#| 2018|A | 92| 71|
#| 2019|A | 39| 92|
#| 2020|A | 64| 39|
#| 2015|B | 25| NA|
#| 2016|B | 21| 25|
#| 2017|B | 17| 21|
#| 2018|B | 59| 17|
#| 2019|B | 38| 59|
#| 2020|B | 97| 38|As you can see in this situation with dplyr, the advantage is that you don’t have unnecessary columns.
Leave a Reply