
Sometimes there are multiple possible strings that you can locate in text. If you would like to extract text in R based on the first match of multiple strings, this post is for you.
Here is my data frame. I will extract text before “On Mon”, “On Sunday”, etc.
df <- data.frame(
text = as.character(c("This is a text that is needed. On Mon, 2 Nov 2020 at 08:44 some other stuff "
, "Hi again, here is anothre one. On Saturday 24 Oct 2020, at 10:36 --Original Message--"
, NA
, "This is another response On Fri, Oct 30, 2020, at 17:36 blah blah blah"
, "ready to proceed On Thu, Oct 8, 2020, at 10:55 Have a nice day!"))
)
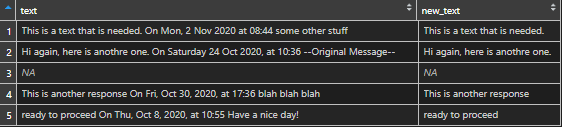
# text
#1 This is a text that is needed. On Mon, 2 Nov 2020 at 08:44 some other stuff
#2 Hi again, here is anothre one. On Saturday 24 Oct 2020, at 10:36 --Original Message--
#3
#4 This is another response On Fri, Oct 30, 2020, at 17:36 blah blah blah
#5 ready to proceed On Thu, Oct 8, 2020, at 10:55 Have a nice day!
Capture first match with multiple strings in R
First of all, you should capture the first occurrence of multiple possible substrings. You can do that with function str_locate from the stringr package. The key is how you create the pattern that is used in the function to find necessary locations. You can do that by separating pattern elements with an OR operator like this.
pattern <- paste(c("On Mon"
, "On Tue"
, "On Wed"
, "On Thu"
, "On Fri"
, "On Sat"
, "On Sun"), collapse = '|')
A technique that I’m using is similar to the one I’m using in this post: How to concatenate text by group in R.
When done, you can extract all of the locations where is the first of the possible strings. Be aware of the empty values. Those are leading to problematic results and should be processed with additional logic. Here is an interesting example with NA caused problems in ifelse.
Extract text based on a match of multiple possible string pattern in R
Here is the final step. Generate a corresponding vector with the location of the first of any of my string parameters. Make simple additional subtraction because R has zero-based numbering.
loc <- ifelse(is.na(df$text), NA, stringr::str_locate(df$text, pattern)) df$new_text <- ifelse(is.na(loc), df$text, substr(df$text, 0, loc - 1))
Here is a more detailed post that explains how to detect different combinations of multiple strings in R.
Leave a Reply